在當今高度數字化的商業環境中,信息系統的穩定運行已成為組織正常運轉的生命線。硬件老化、軟件缺陷、網絡波動、人為操作失誤乃至外部攻擊都可能導致系統故障,影響業務連續性。因此,一套科學、高效、標準化的故障處理機制,是現代信息系統運行維護服務的核心支柱。本文將系統闡述故障處理的策略、標準化流程及關鍵實踐,旨在為運維團隊提供清晰的行動框架。
一、 故障處理的核心策略
- 預防為主,主動運維:最佳的故障處理是避免故障發生。這依賴于完善的監控體系(對服務器性能、應用狀態、網絡流量、日志異常等進行7x24小時監控)、定期的健康檢查、漏洞掃描與修補、容量規劃以及變更前的充分測試。通過趨勢分析預測潛在風險,變“救火”為“防火”。
- 快速響應,最小化影響:當故障發生時,首要目標是快速恢復服務,最大限度減少對業務的中斷時間和影響范圍。這需要明確的應急預案、熟練的技術團隊以及高效的溝通機制。
- 根因分析,治標更治本:故障恢復后,工作并未結束。必須進行深入的根因分析,查明故障發生的根本原因,并實施有效的糾正與預防措施,防止同類故障再次發生,實現運維能力的持續改進。
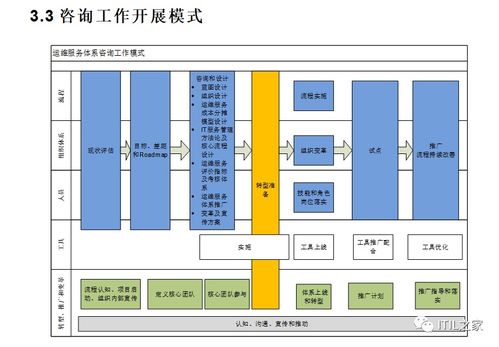
二、 標準化的故障處理流程
一個成熟的故障處理流程通常遵循以下閉環步驟:
- 故障發現與告警:通過監控工具自動告警、用戶反饋、巡檢發現等渠道識別故障。告警信息應準確、及時,包含故障現象、發生時間、影響系統/服務等關鍵信息。
- 故障受理與定級:運維服務臺或值班工程師統一受理告警,根據預設的故障等級標準(通常依據影響范圍、業務關鍵程度、恢復時長要求等因素劃分,如P1-P4級)進行初步定級,并分派給相應的技術支持小組。
- 初步診斷與應急恢復:技術工程師接到任務后,利用知識庫、診斷工具和經驗,快速定位故障點。優先采用已知的、標準的應急恢復操作(如重啟服務、切換備用線路、回滾變更等)恢復服務。此階段需詳細記錄所采取的操作。
- 詳細排查與根因分析:服務臨時恢復后,組織相關人員進行深入排查。利用日志分析、代碼審查、網絡抓包等手段,找到導致故障的根本原因。常用方法包括“5個為什么”分析法、魚骨圖等。
- 制定并實施解決方案:根據根因分析結果,制定徹底的修復方案(如修復Bug、更換硬件、優化配置、調整架構等),并在嚴格的變更管理流程下實施。對于復雜問題,可能需要進行方案評審。
- 驗證與關閉:修復完成后,必須驗證故障是否被徹底解決,系統功能與性能是否完全恢復正常。經業務方或相關干系人確認后,方可正式關閉故障工單。
- 復盤與改進:對于重大或典型故障,應組織復盤會議,編寫《故障復盤報告》。報告需涵蓋故障時間線、影響、根因、處理過程、經驗教訓以及具體的改進措施(如完善監控項、修改應急預案、優化架構、加強培訓等),并跟蹤改進措施的落實。
三、 關鍵最佳實踐
- 建立完善的知識庫:將常見的故障現象、診斷步驟、解決方案沉淀到知識庫中,加速新手成長和問題解決速度。
- 清晰的溝通與升級機制:建立內部團隊間、以及與業務/客戶之間的透明溝通渠道。明確不同故障等級下的通報對象、頻率和內容。對于超時未解決的故障,應有自動升級流程。
- 工具鏈賦能:善用集監控、告警、工單、自動化腳本、日志分析于一體的運維平臺(如ITSM、AIOps工具),提升處理效率。
- 定期演練:針對核心系統的災難場景和重大故障預案,進行定期的模擬演練,檢驗流程的有效性和團隊的響應能力。
- 量化與度量:跟蹤MTTR(平均恢復時間)、MTBF(平均無故障時間)、故障數量、重復故障率等關鍵指標,用數據驅動運維優化。
信息系統故障處理絕非簡單的技術排錯,而是一個融合了流程、技術、人員和管理的系統工程。構建并持續優化一個以預防為基礎、以快速恢復為導向、以根因治理為閉環的故障處理體系,是保障信息系統高可用、高可靠,并最終支撐業務穩健發展的關鍵所在。運維團隊的價值,正是在于通過每一次高效的故障處理,將技術風險對業務的沖擊降至最低,并轉化為系統韌性與團隊能力的不斷提升。